The Java Virtual Machine (JVM) is an integral part of the Java platform and is responsible for executing Java code. It provides a platform-independent environment for running Java applications, allowing developers to write code once and run it anywhere. Understanding how the JVM works is essential for Java developers to optimize performance and ensure the reliability of their applications.
In this tutorial, we will explore the architecture of the JVM, including its memory management, garbage collection, bytecode, and JIT compiler. We will also cover the differences between compiled and interpreted languages, and how the JVM executes Java code. Finally, we will discuss performance tuning techniques for optimizing the performance of Java applications running on the JVM. Let’s dive in!
Understanding How Code is Executed
Each type of processor has its own unique machine language, which it can only execute. Although it’s technically possible to write a program using machine language, it’s impractical and prone to errors, even for the simplest programs.
That’s why almost all programs are written in high-level languages, which are designed to be easily understood by humans. Some examples of high-level languages include Java, C, C++, C#, and Pascal.
However, programs written in high-level languages can’t be executed directly on a computer. They need to be translated into machine language first, using a special type of computer program called a compiler. The compiler takes in a high-level program and translates it into a machine-executable program, which can be executed multiple times.
If you want your program to run on a computer with a different type of processor, you need to re-compile it using a different compiler that can generate the appropriate machine language. Alternatively, you can use a process called interpretation, which involves using an interpreter to translate and execute the program command-by-command, as needed.
An interpreter is a program that works similarly to a processor in a “take command and execute” cycle. For program execution, the interpreter takes one high-level program command, determines the necessary machine operations for its execution, and performs them. However, if a command can’t be executed according to the logic of the program, it won’t be translated.
Moreover, if a block of code is executed multiple times, it’ll be interpreted multiple times, which is why interpretation is typically slower than executing a pre-translated machine language program.
Compiled vs. Interpreted Languages
There are two main approaches to executing code: compilation and interpretation. Compiled languages are transformed into machine code before execution, while interpreted languages are executed directly by an interpreter. Java is often described as a compiled language because it uses a bytecode format, which is compiled from source code, but is not directly executable by the machine. Instead, the bytecode is interpreted by the JVM at runtime.
Compiled Languages
Compiled languages are transformed into machine code, which is directly executable by the machine. This makes them generally faster than interpreted languages, because the machine does not need to perform interpretation at runtime.
The process of compiling a program usually involves several steps, including lexical analysis, parsing, semantic analysis, code optimization, and code generation. The resulting machine code is specific to the hardware architecture and operating system for which it was compiled, making it less portable than interpreted code.
Some examples of compiled languages include C, C++, and Fortran.
Interpreted Languages
Interpreted languages are executed directly by an interpreter, which reads and executes the code one line at a time. This can make them slower than compiled languages, because the interpreter needs to perform interpretation at runtime. However, interpreted languages can be more portable than compiled languages, because the interpreter can be written to run on any platform.
Some examples of interpreted languages include Python, Ruby, and JavaScript.
Java as a Compiled-Interpreted Language
Java is often described as a compiled language because the source code is compiled into bytecode before execution. However, the JVM interprets the bytecode at runtime, making it also an interpreted language. This approach combines the benefits of both compiled and interpreted languages, providing the speed of compilation and the portability of interpretation.
Additionally, the JVM includes a Just-In-Time (JIT) compiler that compiles frequently executed bytecode into machine code, improving performance even further. We will talk about the JIT compiler later in detail later in this tutorial.
What is a Virtual Machine?
Virtual machines (VMs) are software implementations of physical machines that execute programs in a platform-independent environment, providing an abstraction layer between hardware and software. This enables the same code to be executed on different operating systems and hardware architectures.
VMs can be thought of as self-contained operating systems that run on top of a host operating system. They offer a virtualized environment for running applications, including a virtual CPU, memory, and storage, as well as a set of APIs that applications can use.
These virtual machines are used in various contexts, such as server virtualization, desktop virtualization, and cloud computing. In server virtualization, they allow for multiple virtual servers on a single physical server. In desktop virtualization, they provide a virtual desktop environment that can be accessed from any device. In cloud computing, they deliver scalable and flexible infrastructure for running applications in the cloud.
One specific example of a VM is the Java Virtual Machine (JVM), which is designed to execute Java bytecode and provide a platform-independent environment for running Java applications. The JVM offers a virtualized environment for running Java programs, including a virtual CPU, memory, and storage, as well as a set of libraries and APIs that Java applications can use. By providing a platform-independent environment for executing code, virtual machines like the JVM have revolutionized software development by enabling developers to write code once and run it anywhere.
Java Code Execution and the use of Java Virtual Machine (JVM)
The Java programming language uses a combination of compilation and interpretation approaches to execute code.
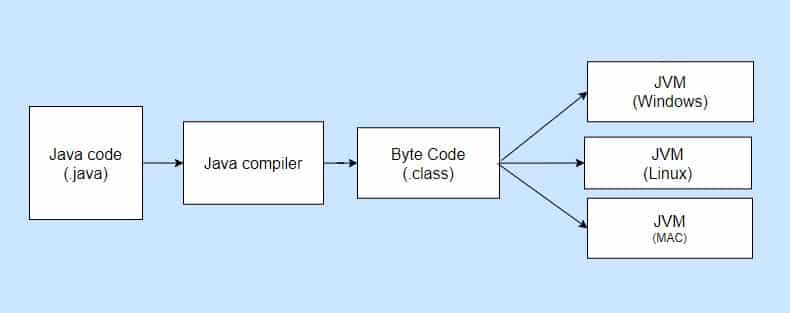
As shown in the picture above, programs written in Java are compiled into machine language. However, this machine language is not specific to any physical processor; instead, it is designed for a virtual computer known as the Java Virtual Machine (JVM). The machine language of the JVM is called Java bytecode. When a Java program is compiled, it is translated into JVM machine language, which cannot be executed directly on a physical computer.
To run a Java program translated into Java bytecode, you need a Java bytecode interpreter installed on your computer, which comes bundled with the JVM. Different versions of the JVM require different Java bytecode interpreters, but only one translation of a Java program into Java bytecode is necessary. This is one of the key advantages of Java compared to other programming languages: the same compiled Java program can be executed on different types of computers.
To execute Java bytecode on your computer, you need to install the appropriate version of the Java Runtime Environment (JRE). Check out this tutorial JRE, JDK, and JVM: Understanding Differences and Uses to gain a deeper understanding of the differences between a JVM, a JRE, and a JDK.
Java Virtual Machine Architecture
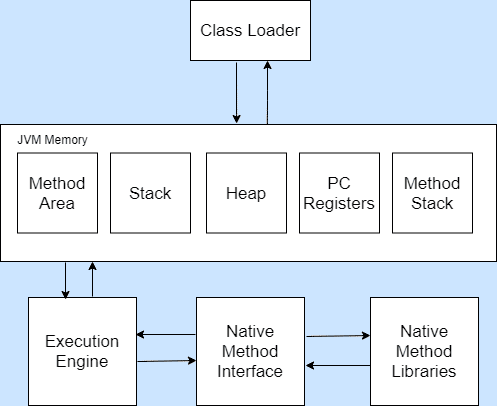
Class Loader: Loads classes for execution.
Method Area: Stores pre-class structures as a constant pool.
Stack: Local variables and partial results are stored here. Each thread has a private JVM stack that is created when the thread is created.
Heap: The heap is a memory area in which objects are allocated.
PC Registers: Holds the address of the JVM instruction currently being executed.
Method Stack: Contains all native methods used in the application.
Execution Engine: Controls the execution of instructions. It contains:
- Virtual CPU
- Interpreter: Reads and executes Java bytecode.
- Just-In-Time (JIT) compiler: The JIT compiler is activated at run-time, not before code execution. So, only the code that is currently executing will be compiled by the JIT compiler, which is why it is called the Just in Time compiler. Once the JIT compiles the code, that version is stored in memory and later used as needed rather than being recompiled. This significantly improves performance.
Native Method Interface: Provides an interface between Java code and native code during execution.
Native Method Libraries: Native libraries consist of files required to execute native code.
Memory Management
The JVM manages memory through automatic memory allocation and garbage collection. When a Java program is executed, the JVM allocates memory in two different areas: the heap and the stack.
- Heap: The heap is the area of memory where objects are allocated. When a new object is created, memory is allocated from the heap to store the object’s data. The JVM automatically manages the allocation and deallocation of memory in the heap through a process known as garbage collection. Garbage collection is the process of identifying objects that are no longer being used by the program and freeing up the memory that they occupy so that it can be reused by the program.
- Stack: The stack is the area of memory where the JVM stores data for method invocations. Each thread in a Java program has its own stack, which is created when the thread is started. The stack stores local variables and partial results for each method that is invoked by the thread. When a method completes, the data that was stored on the stack is removed.
In addition to automatic memory allocation and garbage collection, the JVM also provides a mechanism for explicitly deallocating memory. This mechanism is called finalization, and it allows objects to perform any necessary cleanup before they are removed from memory. When an object is no longer needed, the JVM invokes its finalizer method before deallocating its memory.
By managing memory automatically, the JVM helps to reduce the likelihood of memory-related errors in Java programs. However, it’s still important for developers to be aware of memory usage in their programs and to optimize their code to use memory efficiently.
Garbage Collection
One of the key features of the JVM is its ability to automatically manage memory through garbage collection. Garbage collection is the process of identifying and removing objects that are no longer needed, freeing up memory that can be used for other purposes.
The JVM uses a mark-and-sweep algorithm to perform garbage collection. The mark phase involves identifying all objects that are still in use, starting with the root set of objects (such as local variables in currently executing methods and static fields). The JVM marks these objects and any objects they reference as being in use. Objects that are not marked as in use are considered garbage.
Once the mark phase is complete, the sweep phase identifies all of the garbage objects and frees up the memory that they were using. The garbage collector in the JVM is highly optimized to minimize the impact on application performance.
Garbage collection in the JVM is transparent to the application developer, but understanding how it works can help you write better-performing code. For example, it’s a good idea to avoid creating unnecessary objects that will later be identified as garbage, as this can slow down garbage collection and impact application performance.
Additionally, if you are working with large amounts of data, you may need to adjust the heap size to ensure that there is enough memory available for the garbage collector to work efficiently.
In summary, garbage collection is an important aspect of the JVM’s memory management capabilities. Understanding how it works can help you write more efficient and effective Java code.
Class Loading and Initialization
The Java Virtual Machine (JVM) loads and initializes classes on an as-needed basis, which is known as “lazy loading.” This means that a class is not loaded until it is first used in the application.
Class Loading
When a class is needed for the first time, the JVM uses the class loader subsystem to locate and load the class. The class loader subsystem is responsible for finding the class file and creating a binary representation of the class in the JVM’s memory. There are three built-in class loaders in the JVM:
- Bootstrap class loader: This loads the core Java classes that are included in the JVM itself.
- Extension class loader: This loads classes that are part of the Java Extension Mechanism, which allows developers to extend the functionality of the JVM.
- Application class loader: This loads classes that are part of the application being executed.
In addition to these built-in class loaders, developers can also create their own custom class loaders to load classes from other sources, such as network resources or custom file formats.
Class Initialization
Once a class has been loaded into memory, it is initialized by the JVM. During initialization, the JVM ensures that all static variables are initialized to their default values, and that all static blocks and initializers are executed in the order in which they appear in the code. If a class has any superclass or superinterface that has not yet been initialized, those classes are initialized first.
Class initialization is performed automatically by the JVM, and there is no explicit method call required. However, developers can also provide their own initialization code by defining a static block or initializer in the class.
It’s important to note that class initialization can be a time-consuming process, especially for classes with large amounts of initialization code or complex class hierarchies. To avoid performance issues, it’s important to design classes with initialization in mind and to keep initialization code as simple and efficient as possible.
Bytecode
Java code is compiled into bytecode, which is a set of instructions that the JVM can understand and execute. Bytecode is a binary format that is designed to be platform-independent, meaning that the same bytecode can be executed on any device or operating system that has a JVM installed.
The Java compiler generates bytecode from source code, and this bytecode is then executed by the JVM. Each bytecode instruction corresponds to a specific action, such as loading a value onto the stack, performing an arithmetic operation, or calling a method.
Here’s an example of some Java code and the bytecode that it generates:
Java code:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
Bytecode:
0: ldc #2 // String Hello, World! 2: invokevirtual #3 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 5: return
In this example, the bytecode consists of three instructions:
ldc: This instruction loads a constant value onto the stack. In this case, the constant value is the string “Hello, World!”.invokevirtual: This instruction calls a method on an object. In this case, it calls theprintlnmethod on theSystem.outobject, which prints the string to the console.return: This instruction returns from the method.
The JVM executes these bytecode instructions in order, just as the Java code would be executed if it were run directly.
One of the benefits of bytecode is that it can be optimized by the JIT compiler. The JIT compiler can analyze the bytecode and generate machine code that is optimized for the specific platform on which the code is running. This can result in significant performance improvements, especially for code that is executed frequently.
JIT Compiler
To begin with, let’s talk about the Just-In-Time (JIT) compiler, which is a component of the Java Virtual Machine (JVM). It is designed to enhance the performance of Java applications by dynamically compiling bytecode into machine code that can be executed directly by the CPU. The JIT compiler is activated at runtime, and only the code that is currently executing will be compiled, hence its name, Just-In-Time compiler.
What makes the JIT compiler so essential for Java applications is that it operates at different levels of optimization, which is known as the tiered compilation model. In this model, the JIT compiler first compiles code at a low level of optimization, tier 0, to get the code running quickly. Then, as the code runs, the JIT compiler recompiles the code at higher levels of optimization, tier 1 and tier 2, to further improve performance.
Moreover, the JIT compiler includes several optimization techniques like inlining, loop unrolling, and common subexpression elimination. These techniques help reduce the number of instructions that need to be executed, further enhancing the performance of Java applications.
In conclusion, the JIT compiler is a crucial component of the Java Virtual Machine, improving the performance of Java applications. By compiling bytecode into machine code at runtime and dynamically optimizing code, the JIT compiler can deliver excellent performance for CPU-intensive tasks.
The HotSpot JVM
Hotspots are sections of code that are executed frequently and are critical to the performance of a Java application. The Java Virtual Machine (JVM) includes a feature called the HotSpot JVM that is designed to optimize the performance of hotspots.
The HotSpot JVM works by dynamically identifying hotspots and optimizing them at runtime. When the JVM detects a hotspot, it uses a technique called just-in-time (JIT) compilation to convert the bytecode for the hotspot into native machine code that can be executed directly by the CPU. This can significantly improve the performance of the application by reducing the time spent interpreting bytecode.
The HotSpot JVM uses a number of different optimization techniques to identify and optimize hotspots, including:
- Method inlining: This technique involves replacing a method call with the actual code of the method. This can eliminate the overhead of the method call and improve performance.
- Loop unrolling: This technique involves duplicating loop code to reduce the overhead of loop iteration.
- Escape analysis: This technique involves analyzing object allocation to determine if an object can be allocated on the stack instead of the heap. This can improve performance by reducing the overhead of garbage collection.
The HotSpot JVM also includes a feature called adaptive optimization that allows it to dynamically adjust its optimization strategy based on the runtime behavior of the application. This allows the JVM to adapt to changing workload patterns and ensure that hotspots are always optimized for maximum performance.
Consider the following Java code:
public int sum(int a, int b) {
return a + b;
}
public void test() {
int sum = 0;
for (int i = 0; i < 1000000; i++) {
sum += sum(i, i+1);
}
System.out.println(sum);
}
This code contains a hotspot in the sum method, which is called repeatedly in the loop inside the test method. When this code is executed on the HotSpot JVM, the JVM will identify the hotspot and optimize it at runtime.
Here’s how the HotSpot JVM might optimize this code:
- The JVM detects that the
summethod is being called frequently and is a hotspot. - The JVM performs method inlining, which replaces the method call with the actual code of the method. After method inlining, the loop inside the
testmethod looks like this:
for (int i = 0; i < 1000000; i++) {
sum += (i + i+1);
}
- The JVM performs loop unrolling, which duplicates the loop code to reduce the overhead of loop iteration. After loop unrolling, the loop inside the
testmethod looks like this:
for (int i = 0; i < 1000000; i += 2) {
sum += (i + i+1) + (i+1 + i+2);
}
- The JVM performs escape analysis, which determines that the
sumvariable can be allocated on the stack instead of the heap. This reduces the overhead of garbage collection.
By optimizing the hotspot in this code, the HotSpot JVM can significantly improve its performance. Without the optimizations performed by the HotSpot JVM, this code would execute much more slowly, especially for large input values.
Overall, the HotSpot JVM is an important tool for Java developers who want to write high-performance code. By dynamically identifying and optimizing hotspots at runtime, the HotSpot JVM allows Java applications to run faster without sacrificing the portability and safety of the Java platform.
Performance Tuning
One of the benefits of using the JVM is that it includes several features that help to optimize the performance of Java applications. However, there are still steps that developers can take to further improve performance. Here are some tips for performance tuning:
Profiling
Profiling is the process of analyzing an application’s performance to identify performance bottlenecks. Profiling tools can be used to monitor CPU usage, memory usage, and other metrics to help pinpoint areas of the code that are slowing down the application. By identifying these bottlenecks, developers can make targeted optimizations to improve overall performance.
Caching
Caching is the process of storing frequently accessed data in memory to reduce the number of disk reads and writes. In Java, the java.util.HashMap and java.util.LinkedHashMap classes can be used to implement caching. By caching frequently accessed data, developers can improve performance by reducing the amount of time spent accessing data from disk.
Optimizing Memory Usage
The JVM automatically manages memory allocation and garbage collection, but developers can still optimize memory usage to improve performance. One technique for optimizing memory usage is to use immutable objects whenever possible. Immutable objects are objects that cannot be modified once they are created, which makes them easier for the JVM to manage.
Another technique is to use object pooling. Object pooling is the process of reusing objects instead of creating new ones. By reusing objects, developers can reduce the amount of memory allocated and improve performance by reducing the overhead of object creation. For more information on how the String pool works in Java with respect to the JVM, check out this tutorial Mastering Java String: A Comprehensive Tutorial.
Just-In-Time (JIT) Compilation
As mentioned earlier, the JIT compiler is a feature of the JVM that improves performance by compiling Java bytecode into machine code at run-time. However, there are some strategies that developers can use to further optimize JIT compilation.
For example, developers can use the -XX:+PrintCompilation flag to print information about JIT compilation to the console, which can help to identify areas of the code that are not being optimized. Additionally, developers can use the -XX:+AggressiveOpts flag to enable more aggressive optimizations by the JIT compiler.
By implementing these performance tuning techniques, developers can further optimize the performance of Java applications running on the JVM. However, it’s important to remember that performance tuning should be done carefully and methodically, as making hasty optimizations can sometimes have the opposite effect and actually degrade performance.
Conclusion
In conclusion, the Java Virtual Machine (JVM) is a critical component of the Java platform that enables platform-independent code execution. By providing a virtualized environment for running Java applications, the JVM has made it possible for developers to write code once and run it anywhere.
We’ve explored the architecture of the JVM, including its memory management, garbage collection, class loading and initialization, bytecode, and Just-In-Time (JIT) compilation. We’ve also looked at performance tuning techniques that can be used to optimize the performance of Java applications running on the JVM. For more tutorials on Java programming language, do not hesitate to visit the Java Tutorial for Beginners page.